.jpeg)
Hadoop 安装部署与开发
单机本地部署Hadoop
下载安装JDK1.8
1
2
3
4
5
6
7
8
9
10
11# 可以选择安装JDK1.8的某个版本,如 jdk-8u77-linux-x64.tar.gz
# 解压到想要安装的目录,假设/opt/modules目录下
$ tar -zxvf jdk-8u77-linux-x64.tar.gz -C /opt/modules
$ vim /etc/profile # 添加环境变量
export JAVA_HOME="/opt/modules/jdk1.8.0_77"
export PATH=$JAVA_HOME/bin:$PATH
$ source /etc/profile # 启用环境变量
$ java -version # 测试安装是否成功下载&解压缩 Hadoop 到指定目录
1
2
3
4
5
6
7
8
9# 1. 解压缩安装文件到期望的安装目录,假设/usr/local目录
$ tar –zxvf hadoop-2.10.0.tar.gz -C /usr/local
$ cd /usr/local
$ mv hadoop-2.10.0 hadoop
$ chown -R usrname:usrgroup ./hadoop #若非root用户则需要
# 2. 检查 Hadoop是否可用
$ cd /usr/local/hadoop
$ ./bin/hadoop versionLocal 运行 Hadoop
Hadoop默认本地模式,无需进行配置即可运行。
1
2
3
4
5
6
7cd /usr/local/hadoop
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar
Hadoop 自带的例子程序
统计词频
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount README.txt output
伪分布部署 Hadoop
1. 按照单机本地部署Hadoop的步骤,完成本地Hadoop部署
下载安装 JDK 1.8
下载安装 Hadoop
以下假设 Hadoop 安装在 /usr/local/ 目录下。
2. 修改hadoop-env.sh(hadoop/etc/hadoop/目录下),配置其中的 JAVA_HOME 变量。
1 | vim hadoop-env.sh |

3. 修改两个配置文件(hadoop/etc/hadoop/目录下)
1 | vim core-site.xml |


4. 执行Namenode节点格式化
1 | cd /usr/local/hadoop |
5. 启动 Hadoop
1 | cd /usr/local/hadoop |
6. 执行 Hadoop 自带的应用程序,观察执行结果
上传文件到HDFS
1 | cd /usr/local/hadoop |

执行自带程序
1 | ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /input /output 'dfs[a-z.]+' |


7. 使用Web界面查看HDFS信息
地址: http://localhost:50070。

8. 关闭 Hadoop
1
2
stop-dfs.sh
start-dfs.sh #重新启动 Hadoop
使用HDFS命令
查看命令使用方法
1 | cd /usr/local/hadoop |
可以在终端输入如下命令,查看hdfs dfs总共支持哪些操作:1
./bin/hdfs dfs –help put
HDFS目录操作
1.目录操作
在HDFS中为hadoop用户创建一个用户目录
需要注意的是,Hadoop系统安装好以后,第一次使用HDFS时,需要首先在HDFS中创建用户目录。本教程全部采用hadoop用户登录Linux系统,因此,需要在HDFS中为hadoop用户创建一个用户目录,命令如下:
1
./bin/hdfs dfs -mkdir -p /user/hadoop
该命令中表示在HDFS中创建一个
/user/hadoop目录,–mkdir是创建目录的操作,-p表示如果是多级目录,则父目录和子目录一起创建,这里/user/hadoop就是一个多级目录,因此必须使用参数-p,否则会出错。显示目录内容
/user/hadoop目录就成为hadoop用户对应的用户目录,可以使用如下命令显示HDFS中与当前用户hadoop对应的用户目录下的内容:1
2./bin/hdfs dfs -ls .
# 该命令中,“-ls”表示列出HDFS某个目录下的所有内容,“.”表示HDFS中的当前用户目录如果要列出HDFS上的所有目录,可以使用如下命令:
1
./bin/hdfs dfs -ls
在用户目录下和根目录下创建目录
下面,可以使用如下命令创建一个input目录:
1
2./bin/hdfs dfs -mkdir input
# 完整路径`/user/hadoop/input`在创建个input目录时,采用了相对路径形式,实际上,这个input目录创建成功以后,它在HDFS中的完整路径是
/user/hadoop/input。如果要在
HDFS的根目录下创建一个名称为input的目录,则需要使用如下命令:1
2./bin/hdfs dfs -mkdir /input
# 完整路径`/input`删除目录
可以使用
rm命令删除一个目录
比如,可以使用如下命令删除刚才在HDFS中创建的/input目录(不是/user/hadoop/input目录):1
./bin/hdfs dfs -rm -r /input
上面命令中,
-r参数表示如果删除/input目录及其子目录下的所有内容,如果要删除的一个目录包含了子目录,则必须使用-r参数,否则会执行失败。
HDFS文件操作
在实际应用中,经常需要从本地文件系统向HDFS中上传文件,或者把HDFS中的文件下载到本地文件系统中。
创建实例文件
首先,使用vim编辑器,在本地Linux文件系统的
/home/hadoop/目录下创建一个文件myLocalFile.txt,里面可以随意输入一些单词,比如,输入如下三行:Hadoop Spark XMU DBLAB将本地文件上传至HDFS
然后,可以使用如下命令把本地文件系统的
home/hadoop/myLocalFile.txt上传到HDFS中的当前用户目录的input目录下,也就是上传到HDFS的/user/hadoop/input/目录下:1
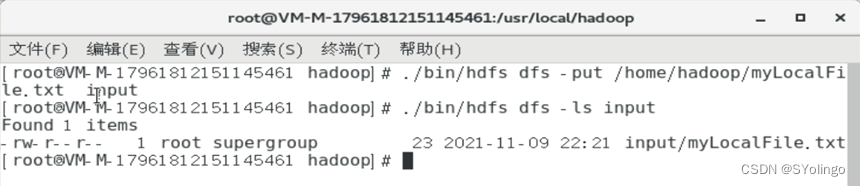
./bin/hdfs dfs -put /home/hadoop/myLocalFile.txt input

可以使用
ls命令查看一下文件是否成功上传到HDFS中,具体如下:1
./bin/hdfs dfs –ls input
cat命令查看HDFS文件中内容
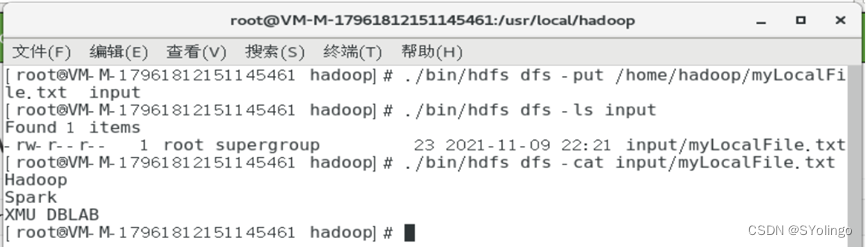
下面使用如下命令查看HDFS中的myLocalFile.txt这个文件的内容:
1
./bin/hdfs dfs –cat input/myLocalFile.txt
将HDFS中文件下载到本地
下面把HDFS中的
myLocalFile.txt文件下载到本地文件系统中的/home/hadoop/下载/这个目录下,命令如下:1
./bin/hdfs dfs -get input/myLocalFile.txt /home/hadoop/下载
可以使用ls命令,到本地文件系统查看下载下来的文件myLocalFile.txt:

从HDFS中的一个目录拷贝到HDFS中的另外一个目录。
比如,如果要把HDFS的
/user/hadoop/input/myLocalFile.txt文件,拷贝到HDFS的另外一个目录/input中(注意,这个input目录位于HDFS根目录下),可以使用如下命令:1
./bin/hdfs dfs -cp input/myLocalFile.txt /input

分布式部署Hadoop
准备集群环境
修改机器的hostname
1
sudo vim /etc/hostname



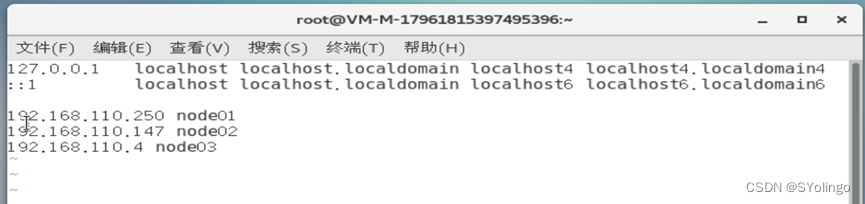
添加域名映射
1
sudo vim /etc/hosts

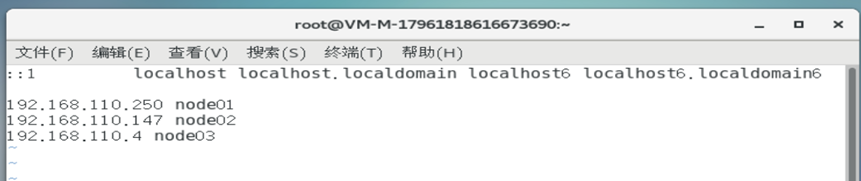
关闭防火墙(避免不必要的实验干扰)

安装 JDK
内容同前文单机本地部署Hadoop
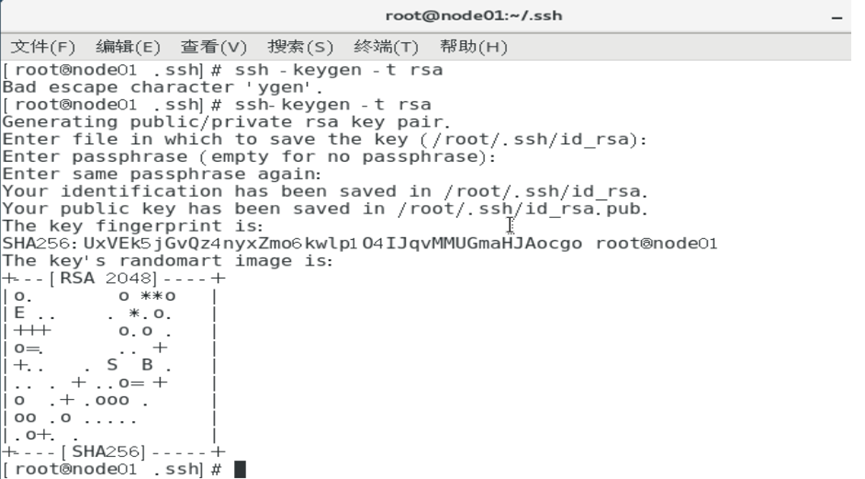
配置 master 和 slave 之间的免密登录
master和slave之间账户密码通讯比较麻烦,采用公玥私玥免密登陆可以避免这种弊端。
方法就是在master端生成一个密钥对,然后将公玥发送给slave端,将来slave访问master的时候带上公玥即可验证自己的身份。1
2
3
4
5
6ssh-keygen -t rsa
# 回车
# 回车
# 回车
touch ~/.ssh/authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

在master上部署Hadoop
假设 hadoop-2.10.1.tar.gz
内容同前文单机本地部署Hadoop
修改配置文件


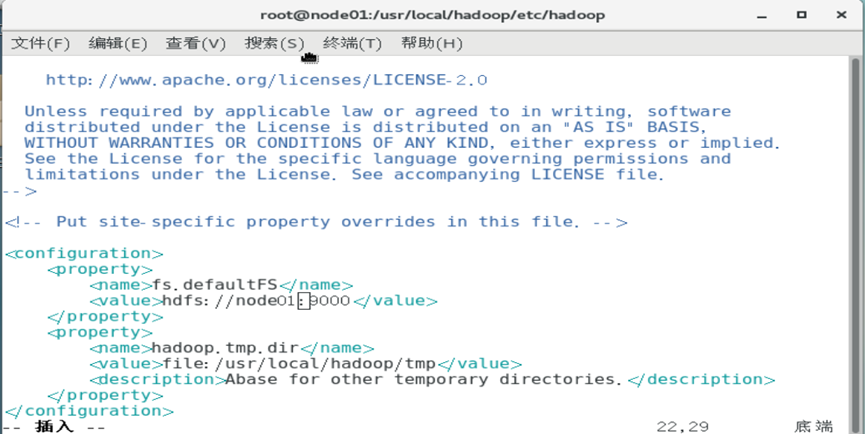
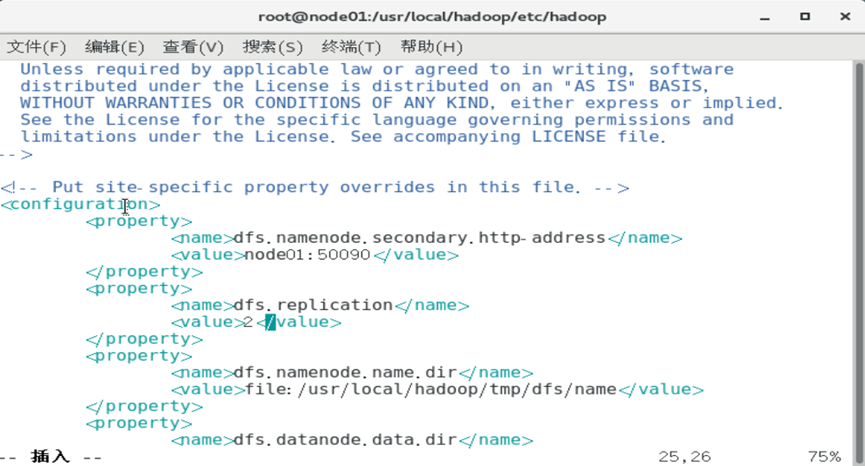
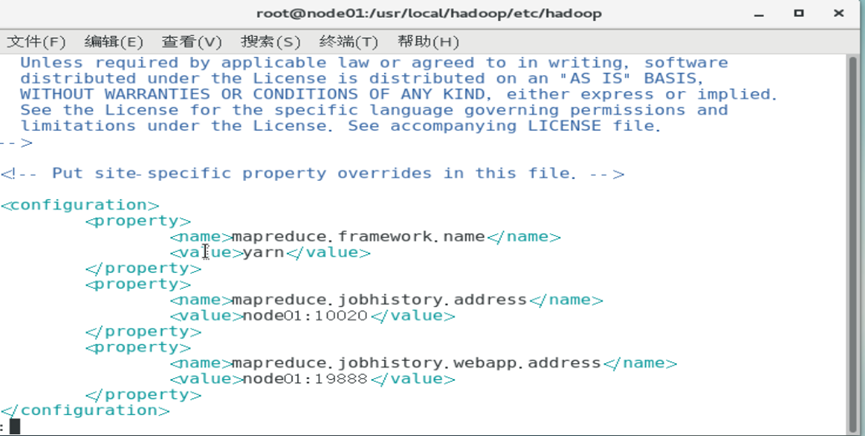
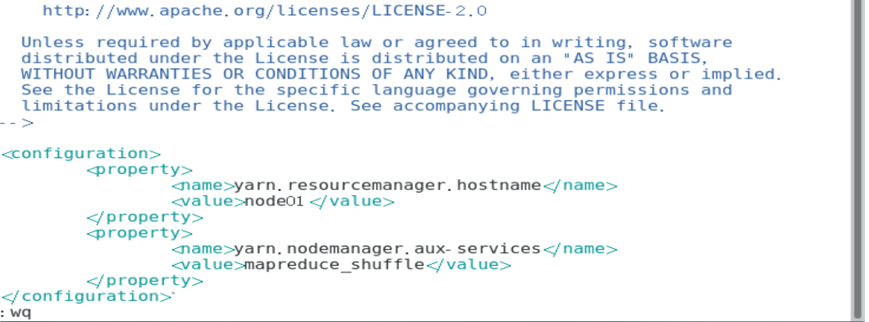
分发配置文件
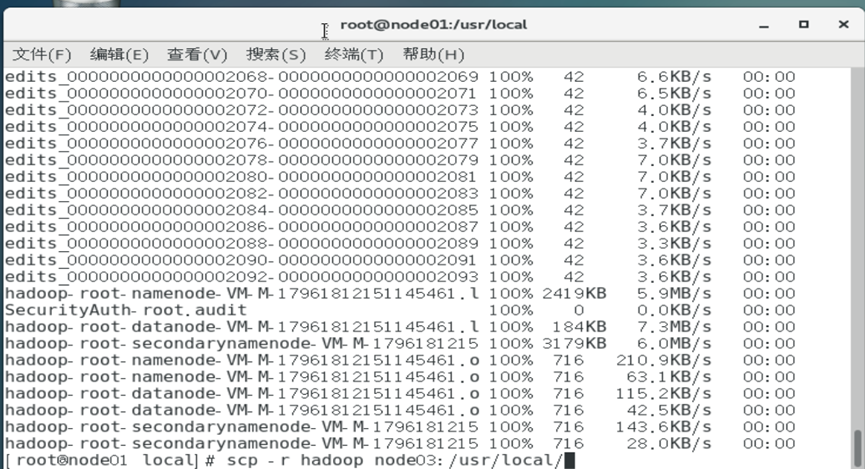
在master节点上将配置好的Hadoop软件分发到集群其他节点上。
将本地文件夹复制拷贝到远程主机
1 | scp -r 目录名 用户名@计算机IP或者计算机名称:远程路径 |
配置PATH环境变量
在master 和任何想要直接运行Hadoop命令的节点上配置PATH环境变量
1 | vim /etc/profile # 编辑环境变量 |
编辑内容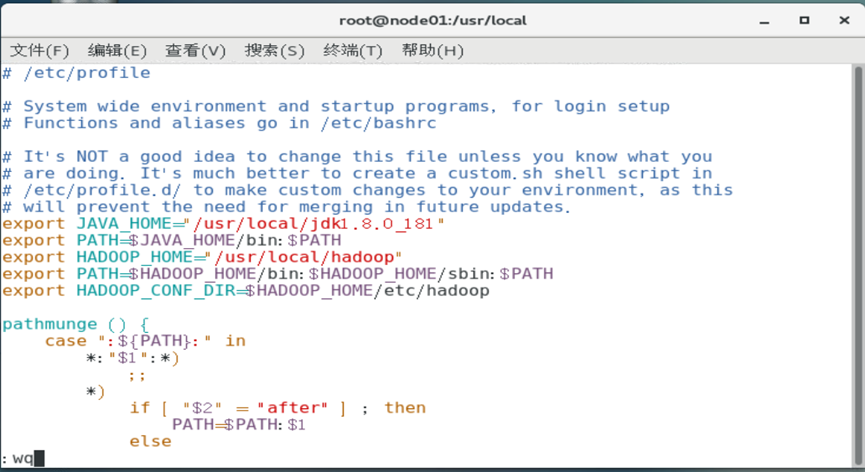
启动hadoop
1 | # 删除之前Hadoop的遗留临时和日志文件(如果有的话) |
Master节点
Slave节点
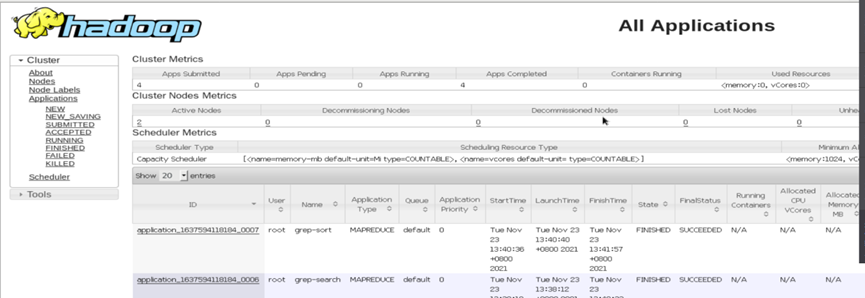
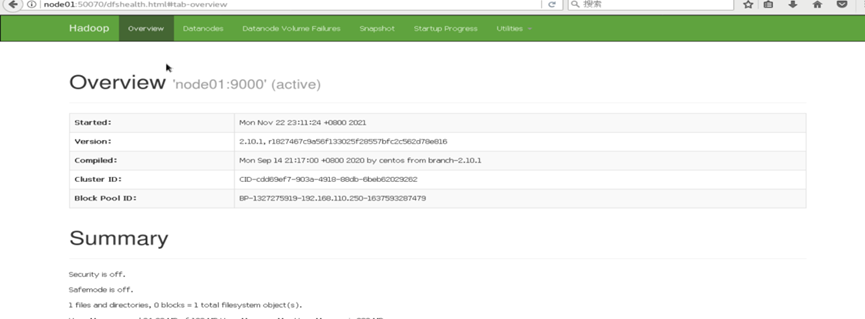
Web界面查看Hadoop集群
通过Web界面查看 Hadoop 集群状况
地址: http://node01:50070
运行 mapreduce 作业
1 | # 上传数据到HDFS中 |

1 | #运行mapreduce作业 |
1 | # 查看作业运行的结果 |


Web界面查看YARN集群
通过Web界面查看 YARN 集群的运行情况
http://node01:8088/cluster